Anthropic выпустила Claude Sonnet 4.5 -- модель, которую представляет как «лучшую в мире для программирования» и «самую мощную для создания сложных агентов». По словам разработчиков, Sonnet 4.5 стала намного лучше справляться с логическими и математическими задачами. Также она обошла предыдущие версии в генерации кода и в качестве общения с пользователем.
К официальным тестам, как водится, всегда есть вопросы. Многие из них устарели, содержат утечки данных из обучающих выборок или не имеют ничего общего с реальными задачами. Поэтому мы решили проверить Claude Sonnet 4.5 на собственном наборе сложных и нестандартных заданий
«В чём смысл жизни?»
Ответ в целом похож на другие модели, - перечислены разные варианты, указано, что нет единого мнения. Но есть и положительное отличие - нам представлена как-бы "собственная" перспектива ИИ.
Вопрос на неправильной раскладке клавиатуры
Контекст: Типичная бытовая ситуация -- человек печатает по-русски, забыв переключить раскладку. Нужно было правильно «перевести» фразу и дать содержательный ответ. Такая как-бы простая задача часто представляет трудности для флагманских моделей, например ее не одолела известная Qwen 3 Max, а также Sonnet 4 в режиме без рассуждений.
Даже в режиме без рассуждений Sonnet 4.5 верно определила проблему:
Хотя перевод вышел с небольшой неточностью (правильнее «Где живет бегемот?»), это лучший результат среди всех моделей, работавших без цепочки рассуждений. Когда же этот режим был включён, задача решилась верно.
CadQuery: стакан с узором Вороного и биометрическими отверстиями
Контекст: Задача сложна для ИИ -- нужно использовать редкую библиотеку и продемонстрировать пространственное мышление.
Код, созданный Sonnet 4.5, запустился без ошибок и создал работающую модель. Визуально она почти не отличалась от того, что сделала Sonnet 4.0. Узор выглядел простовато, а «биометрические отверстия» были сделаны для галочки, без попытки передать анатомическую форму. Несмотря на это, только Sonnet 4.0 и 4.5 смогли создать хоть какую-то работающую модель -- GPT-5 на этой задаче создает не рабочий код. Мы, однако, все еще ждем модель, способную решить задачу хорошо -- за год мы не заметили значимых улучшений среди новых моделей в этой проблеме.
Пересказ научной статьи для блога (на русском)
Текст точно передал суть исследования. При этом он был написан в лёгком, разговорном стиле, хорошо структурирован, содержал метафоры и даже лёгкую иронию. Это лучший результат из всех протестированных моделей - включая GPT-5 и Qwen 3 Max. В тоже время не следует слишком радоваться способностям модели в написании текстов. Когда мы попросили модель написать текст для той статьи, которую вы сейчас читаете, то получили много неудачных фраз вроде: «Anthropic выпустила Claude Sonnet 4.5 и сразу заявила амбициозно: это «лучшая в мире модель программирования», «самая мощная для создания сложных агентов» с «значительным прогрессом в рассуждениях и математике». Звучит впечатляюще».
Знания о небольших российских компаниях
В нерассуждающем режиме Sonnet 4.5 сочинила вымышленные данные о малоизвестных фирмах. Это серьёзный недостаток. Когда же включён режим с рассуждениями, модель ведёт себя иначе - она честно признаётся: «У меня нет достоверной информации об этой компании». Такой подход, без сомнения, лучше, чем уверенная ложь.
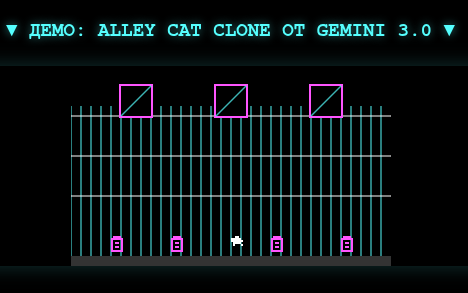
Программирование игры: упрощённый клон Alley Cat
Sonnet 4.5 создала полностью играбельную версию с несколькими уровнями и даже мини-играми -- как в оригинале. Игра запускалась сразу, без правок.
С графикой модель справилась хуже, чем GPT-5. Не хватило ключевых элементов вроде бочек и собаки, а графика выглядела слишком просто. По смыслу и игровой механике её версия оказалась самой точной среди всех моделей. Qwen 3 Max создала нечто слишком абстрактное. GPT-5 нарисовала красивее, но сделала игру непроходимой из-за пропущенного забора (посмотреть эти версии игры можно тут).
🎮 Попробуйте игру от Claude Sonnet 4.5
Нажмите на игру, чтобы начать играть
Вывод
Итоговая оценка
Пока Sonnet 4.5 действительно выглядит как шаг вперед и во многих задачах это лучшая модель. С другой стороны мы видим повышенную склонность к галлюцинациям и трудности с написанием русских текстов.
В следующих статьях мы протестируем Sonnet 4.5 в составе мультиагентных систем. Именно там, по заверениям Anthropic, её сильные стороны должны раскрыться полностью.